|
最近发现自己的歌词数逐渐接近1000,Word文档里的汉字字符数已经二十几万。一方面,继续用Word编辑似乎有些变慢(不知道这方面有什么解法?写长篇小说的朋友们都用什么比较轻量的写作软件?);另一方面,也想对自己的歌词进行一些数据分析,那么表格式数据存储(CSV,XLSX)+每首歌作为一个entry(row,observation)可能更为适合。但是对于1000首歌词+二十万字来说,手工复制粘贴、存储的劳动量,并不现实。于是想到,使用使用R语言简化工作流程。 ##################################### ############## 加载数据包 ############## ##################################### Sys.setlocale(category = "LC_ALL", locale = "US") # setwd("D:/file") library(textreadr) library(xlsx) library(readxl) library(writexl) library(tidyverse) library(tidyr) library(data.table) library(qdap) library(reshape2) library(plyr) library(dplyr) ##################################### ### read in docx file & convert to DATAFRAME ### ##################################### DOC = read_docx(file = "*PATH*/2019.04.08 原创歌词 单页.docx") # View(DOC) DOC1 = data.frame(DOC) # convert to data.frame DOC1 = as.data.table(DOC1) # VIEW DATA with head/tail functions # head(DOC1) tail(DOC1)  ##################################### ## 用关键词检测grepl, 对半结构化文本进行识别 ### ##################################### DOC1$ATTR = NA # create empty variable DOC1$ATTR = ifelse(grepl("chorus", as.character(DOC1$DOC), ignore.case = T), "CHORUS", "REG") # 副歌部分——行识别 # DOC1$ATTR = ifelse(grepl("200", as.character(DOC1$DOC), ignore.case = T), "YEAR", DOC1$ATTR) # 年份——行识别 # DOC1$ATTR = ifelse(grepl("201", as.character(DOC1$DOC), ignore.case = T), "YEAR", DOC1$ATTR) # 年份——行识别 # DOC1$ATTR = ifelse(grepl(":", as.character(DOC1$DOC), ignore.case = T), "TIME", DOC1$ATTR) # 冒号/时间——行识别 # DOC1$ATTR = ifelse(grepl("张汇泉", as.character(DOC1$DOC), ignore.case = T), "AUTHOR", DOC1$ATTR) # 作词人——行识别 # ##################################### ######## 检查歌曲属性、是否识别错误 ######## ##################################### # 检查 # dist_tab(DOC1$ATTR) DOC1$ATTR[10273] # 检查特定行数 # 对于所有行——年份行数之前的一行——识别为歌曲标题 # # 很可能出现大量误差,但1200余行YEAR,989首歌词,# # 误差量大约二百行 doable # for (n in 1:25068) { DOC1$ATTR[n-1][DOC1$ATTR[n] == "YEAR"]="TITLE" } write.xlsx2(DOC1, "D:/1.xlsx") ## 手工调整:把所有TITLE行,漏掉的(约六十行)######### ## 误认的(约二百行)在EXCEL中手工调整、识别、检查 ##### ## 使用筛选、排序、查找、替换等功能。 ################ 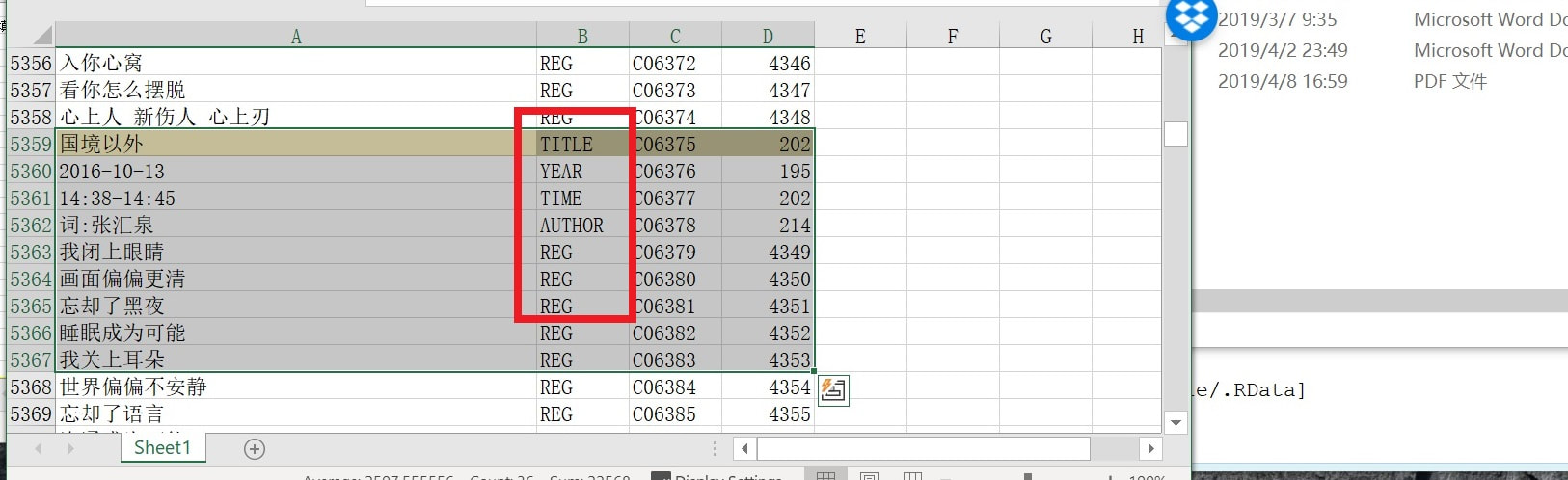 # 可以看到,上图:只要没有特别例外的状况,大多数歌词的区块属性都被准确识别了——标题行(TITLE)、年份行(YEAR)、时间行(TIME)、作者行(AUTHOR)、内容行(REGULAR) #################################### ########## 2019.4.8 read in xlsx ########### #################################### ## 读入手工清理后的 EXCEL数据 ## DOC2 = read.xlsx2("*PATH*/20190408_989SONGS.xlsx", 1) ## 所有TITLE标题之间的行数,都标定为同一个BLOCK. ## DOC2$TITLE_COUNT = sapply(1:length(DOC2$ATTR), function(i) sum(DOC2$ATTR[1:i]== "TITLE")) ## DOC2$NAME = NA DOC2$NAME = DOC2$NAME[match(DOC2$TITLE_COUNT, DOC2$TITLE_COUNT)] writexl::write_xlsx(DOC2, "D:/989songs.xlsx") as.character(DOC2$DOC [DOC2$ATTR=="TITLE"]) ########################################## ###### 2019.4.14 redo_title, long to wide data: ######## ########################################## # 这一步是把20000行歌词LONG to WIDE(长变宽),按照标题分组, # 整合成989首歌词。 # 使用到plyr函数包中的ddply函数,把所有“TITLE_COUNT”相同(也就是从属于同一个歌词BLOCK区块)的文本内容,贴合在一起,成为歌词; # 把第2段(一般来说是年份)、第3段(一般来说是写作时间)都提取出来。 # DOC3 = read.xlsx2("D:/994SONGS.xlsx", 1) DOC3 = readxl::read_xlsx("D:/994SONGS.xlsx", 1) DOC3$TITLE_COUNT = sapply(1:length(DOC3$ATTR), function(i) sum(DOC3$ATTR[1:i]== "TITLE")) DOC4 = plyr::ddply(DOC3, .(TITLE_COUNT), summarize, TXT = toString(DOC)) DOC5 = plyr::ddply(DOC3, .(TITLE_COUNT), summarize, TXT = toString(DOC[1])) DOC6 = plyr::ddply(DOC3, .(TITLE_COUNT), summarize, TXT = toString(DOC[2])) DOC7 = Reduce(function(x,y) merge(x = x, y = y, by = "TITLE_COUNT"), list(DOC4, DOC5, DOC6)) head(DOC7) DOC7$ID = seq(1, length(DOC7$TITLE_COUNT), 1) DOC7$RID = formatC(DOC7$ID, width = 6, flag = 0) DOC7$RID = paste0("SONG_", DOC7$RID) head(DOC7) names(DOC7) names(DOC7) = c("SERIAL", "LYRICS", "TITLE", "TIME", "ID", "RID") DOC7$LYRICS_BY = "张汇泉" DOC7$YEAR = substr(DOC7$TIME, 1, 4) write_xlsx(DOC7, "D:/20190413_lyrics.xlsx") # 结果见下图:成功转换(当然需要一些手动修改和纠错)#  |
